
二者都是经典的分类器,SVM更强调最优化的可分,并且有严密的数学模型支撑。
网上搜了二者的优缺点对比,最终说实话还是一知半解。可能还需要真实场景实践,也许能够深入理解二者区别吧。
支持向量机的优势在于:
- 在高维空间中非常高效.
- 在线性可分的低维空间,SVM得到的比Logistic Regression更加健壮
- 即使在数据维度比样本数量大的情况下仍然有效.
- 在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的.
- 通用性: 不同的核函数与特定的决策函数一一对应.常见的内核已经提供,也可以指定定制的内核.
支持向量机的缺点包括:
- 如果特征数量比样本数量大得多,在选择核函数时要避免过拟合,而且正则化项是非常重要的.
- 支持向量机不直接提供概率估计,这些都是使用昂贵的五次交叉验算计算的.
支持向量机 VS. Logistic Regression Intuition
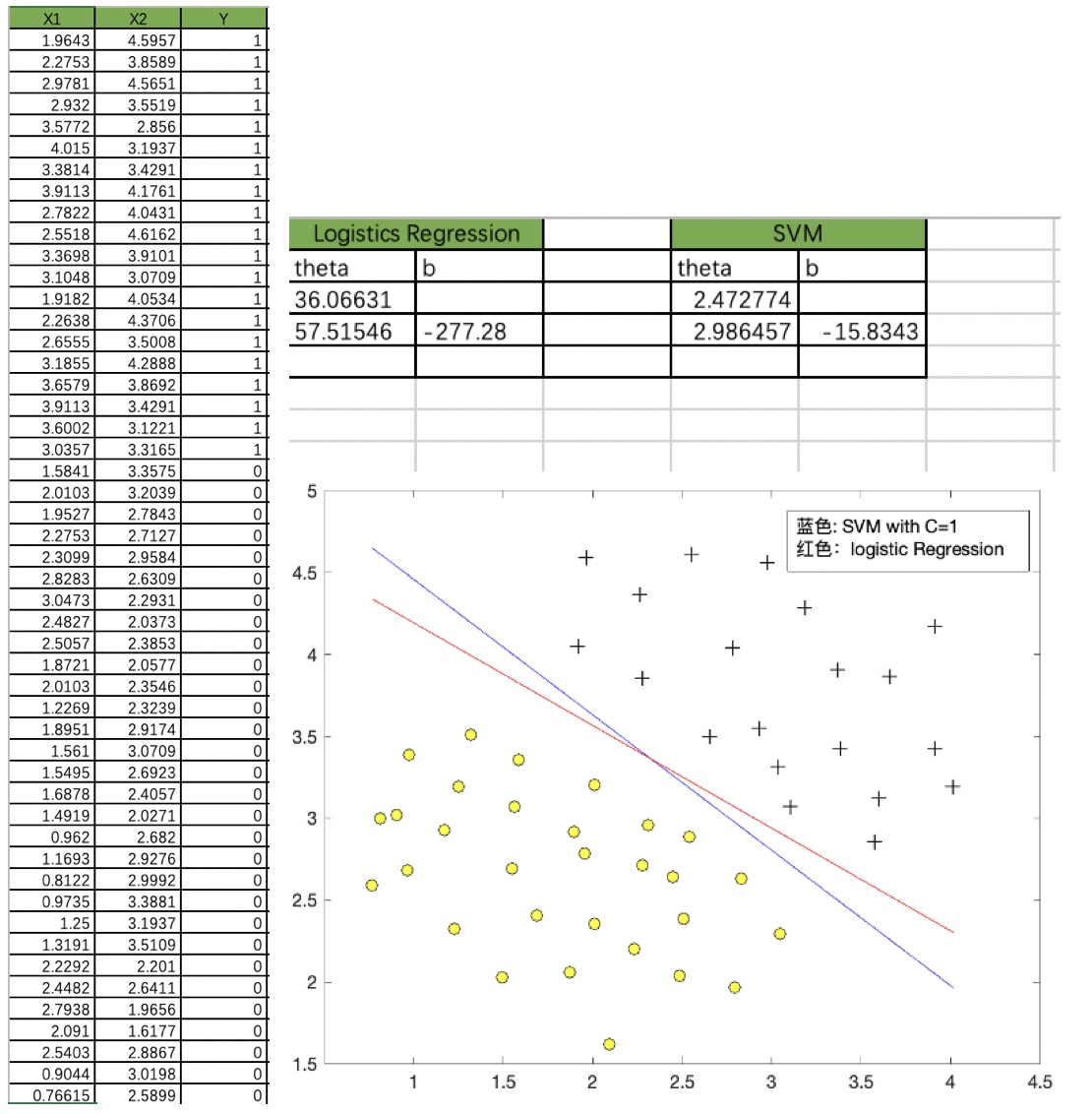
原始数据集:X1、X2、Y
通过SVM Linear和SMO算法得到最优化边界(蓝色),和对应的w、b
通过Logistic Regression得到w和b
画出两种情况下的decision boundary,明显看到SVM更加robust,泛化能力更好。这是对于线性硬可分的支持向量机来看,如果是线性不可分或者更复杂的场景,也许结果有可能不同。
暂无评论